Kafka日志存储
日志目录
对于一个主题,可以有多个分区,每个分区可以有多个副本,每个副本都有一个日志。为了防止日志过大,Kafka引入了日志分段 (LogSegment)的概念,如下图所示。
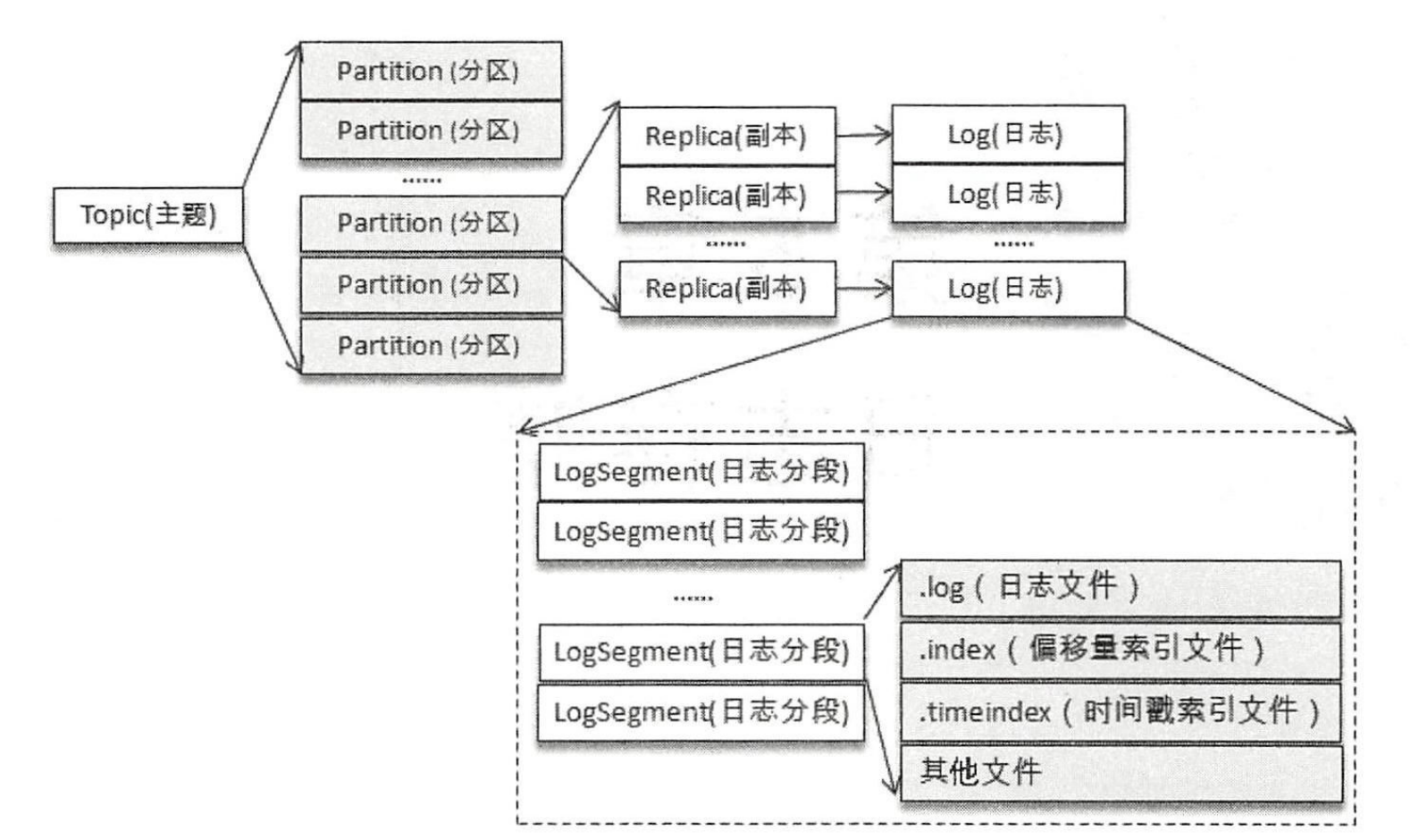
可以在kafka的日志目录下找到topic-partition的文件夹,在其中就可以看到这几个日志文件。
在.log文件中存放的日志文件,每个日志文件还有两个对应的文件 (.index文件和.timeindex文件)。这3个文件都是以第一条消息偏移命名的,固定为20个数字(如: 00000000000000000000.log)。PS: 还有其它几个文件,这里重点关注这三类文件。
日志格式
v0版本
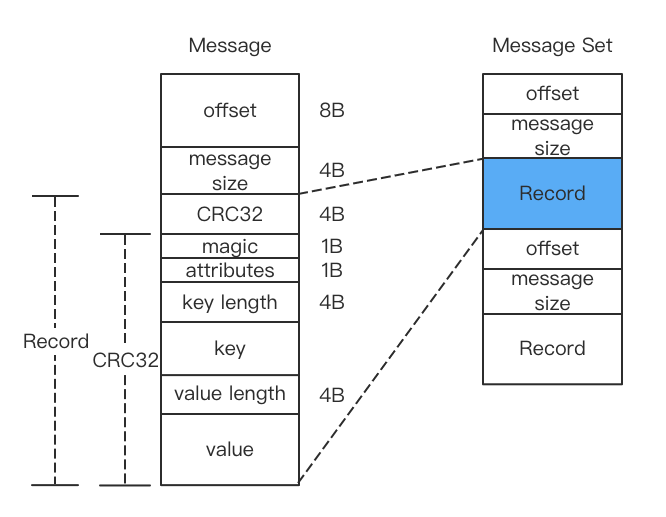
offset (8B): 表示当前消息的偏移(逻辑值,非物理偏移)message size (4B): 表示消息的大小
这两个是消息的控制信息,接下来看看消息的具体内容
crc32 (4B): crc32校验值,校验范围为magic~valuemagic (1B): 消息格式版本号,此版本为0attributes (1B): 低3位表示压缩类型(0:NONE,1:GZIP,2:SNAPPY,3:LZ4),其余位保留key length (4B): 表示key的长度,若为-1,表示是key为空key: 键value length (4B): 表示消息值的长度,若为-1,表示消息为空value: 消息值
v1版本
v1版本相较于v0版本添加了时间戳字段
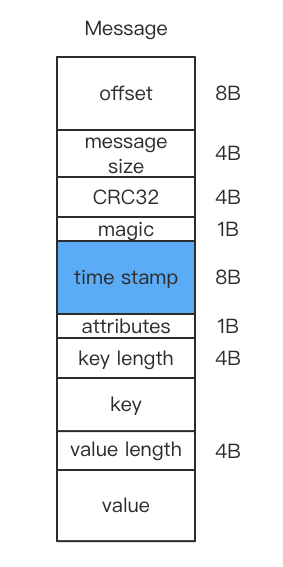
另外,将attributes的第4位利用了起来,0表示timestamp为消息创建时间 (CreateTime),1表示timestamp为追加日志时间 (LogAppendTime)。这个类型由broker端的log.messsage.timestamp.type设置,默认是创建时间。
引入timestamp的原因
详情可参考kip-32,主要是为了解决3个问题:
- 日志保存: 如果没有时间戳,在日志分段的情况下,其时间会被认为是文件最后修改的时间。但是,遇到副本重分配 (副本迁移等)会将这个时间刷新,如果要设置日志文件的保留时间,这就会发生错误。
- 日志切分: 原因同上
- 流处理。很多流处理系统需要时间戳
消息压缩
因为小数据的压缩效果不是很好,所以Kafka将多条消息一起压缩。在Kafka中,处理的消息都是消息集合,在Pruducer会将消息集合压缩,Broker将其当成一个消息存储,在消费者端进行解压。下图是压缩消息的存储。PS: 在有些情况下broker会进行解压操作,如Broker设置的压缩算法与Producer不一致。
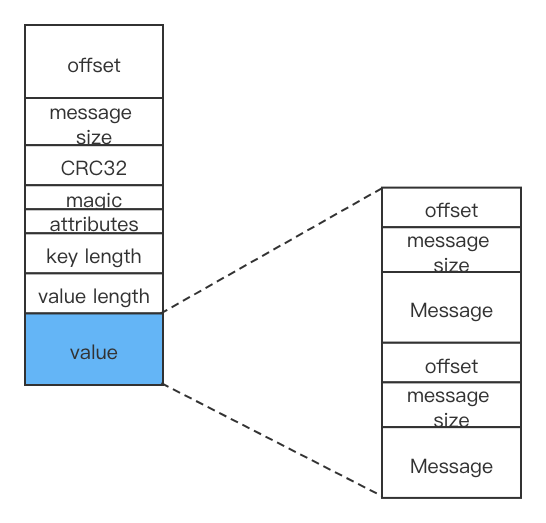
内层消息的offst从0开始,外层消息的offset取未压缩情况下最后一条消息的offset。
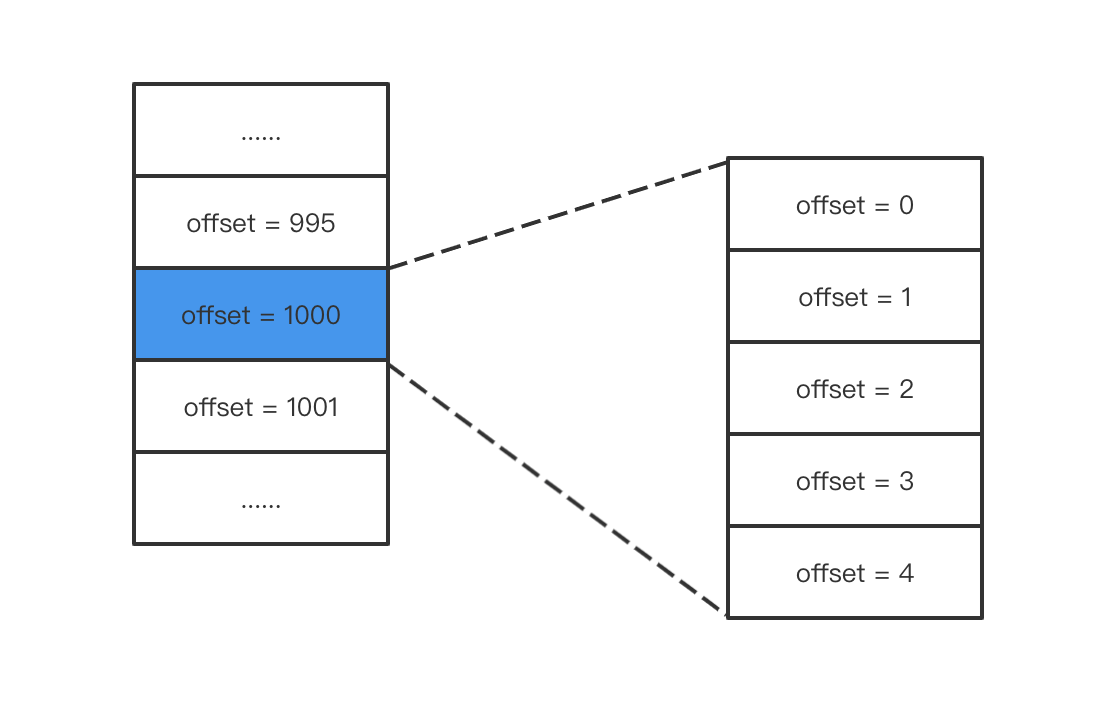
当消费者消费时,先解压缩整个消息集合,找到最后一条消息,然后再找需要消费的那条消息的偏移。例如找offset为998的消息,先找到offset为1000的消息集合,再找集合中偏移为 998-1000 = -2 的偏移(相对最后一条消息)。
压缩算法和性能对比可参考: https://www.cnblogs.com/huxi2b/p/10330607.html
v2
V2对之前的消息进行比较大的改版,其主要的3个数据结构如下图所示:
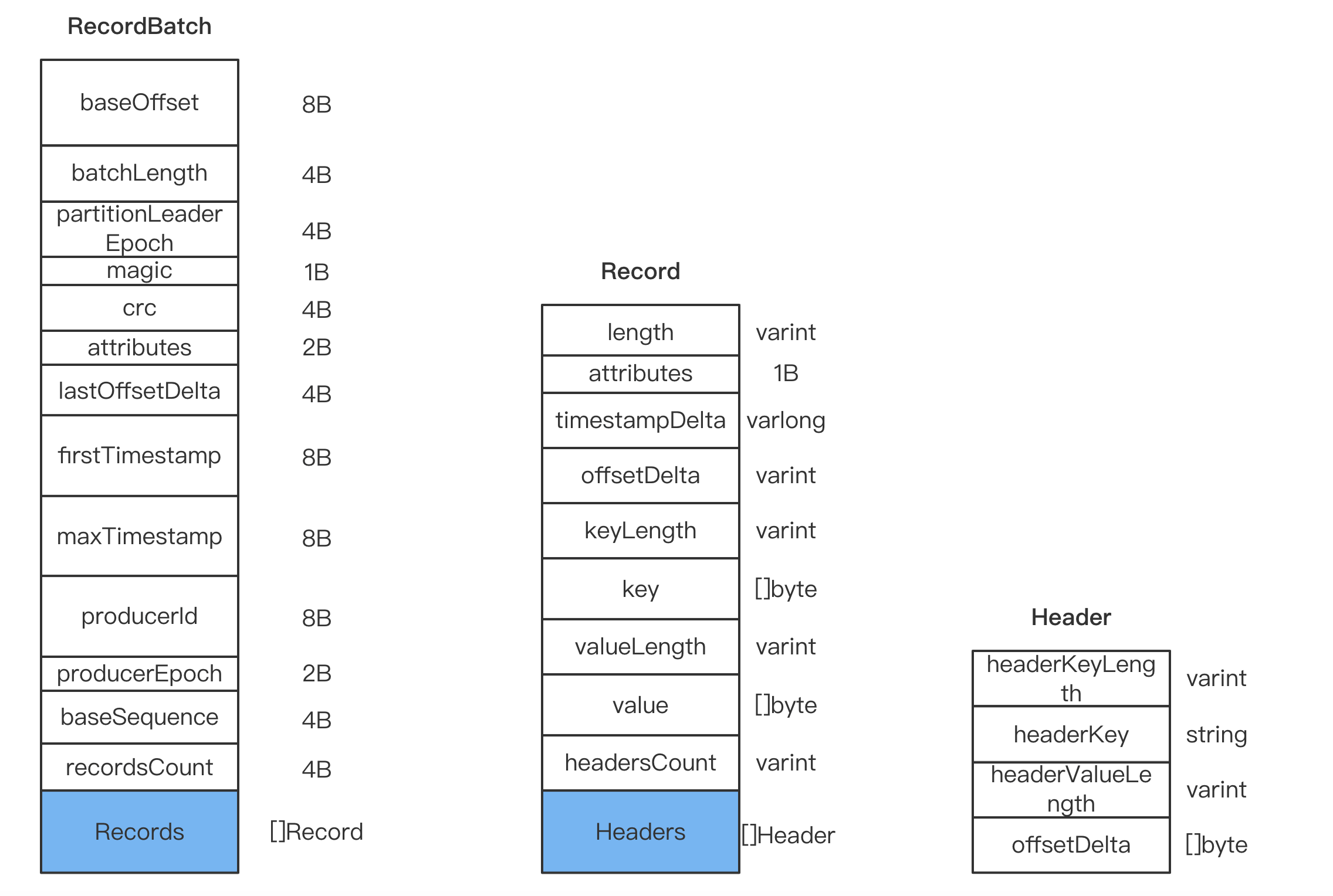
RecordBatch
之前说了,消息是以消息集合的形式传递的,V2中对消息集合进行了修改,用RecordBatch表示,各字段含义如下:
baseOffset (8B): 当前RecordBatch的其实偏移batchLength (4B): 保存从partition leader epoch开始到最后的长度partitionLeaderEpoch (4B): 分区leader的版本号magic (1B): 消息格式版本号,此版本为2crc (4B): crc校验,覆盖从attribute到最后attributes (2B): 消息属性,低4位与V1版本一致,第5位表示是否处于事务中,第6位表示是否是控制消息。lastOffsetDelta (4B): 最后一个Record的offset deltafirstTimestamp (8B): 第一条Record的时间戳maxTimestamp (8B): Records中最大的时间戳producerId (8B): 用来支持幂等和事务producerEpoch (2B): 同上baseSequence (4B): 同上recordsCount (4B): 包含Record的个数
Record
Record部分和之前的相差不大,其中部分的释义如下:
length (varint): 当前Record的长度attributes: 弃用,保留字段timestampDelta (varlong): 时间戳增量。保存的是和RecordBatch起始时间的差值offsetDelta (varint): 保存与RecordBatch起始偏移的差值headers: 用来支持应用级的扩展
Record处取消了CRC,将其放到了RecordBatch中
变长整型
在V2格式中,可以看到Record中多了种varints的格式,例如length等都不再固定大小了,而是使用的varints格式,也即变长整型。
varints中每个字节的最高位为标志位,除最后一个字节外,都设置为1,最后一个字节设置为0。另外,varints使用的是小端序,即小的字节在前面。详情可参考 https://developers.google.com/protocol-buffers/docs/encoding
例如300:
1010 1100 0000 0010
正常二进制表示为 0000 0001 0010 1100
对于负数,例如-1,如果采用这种方式的话,会浪费较多空间。所以varint有符号整数使用的ZigZag编码,该编码方式使用正负数交叉的方法,如下所示:
| Signed Original | Encoded As |
|---|---|
| 0 | 0 |
| -1 | 1 |
| 1 | 2 |
| -2 | 3 |
| 2147483647 | 4294967294 |
| -2147483648 | 4294967295 |
对32位有符号整数n,其编码代码为:
1 | (n << 1) ^ (n >> 31) |
64位有符号整数类似:
1 | (n << 1) ^ (n >> 63) |
相当于正数*2,负数则取绝对值*2-1。
然而使用varint并不意味着省空间,对于较大的数字,可能更占空间。因为对于int32,最长需要使用5个字节,因为每个字节需要一个标志位,只有7位能表示值,而int64最长会占用10个字节。
具体的消息示例
向一个topic连续发5个key=tech,value=for good的消息(可以设置5个消息组成消息集合,一起发送),去kafka日志中查看消息。
使用命令hexdump -C 00000000000000000000.log ,显示如下
1 | 00000000 00 00 00 00 00 00 00 00 00 00 00 94 00 00 00 00 |................| |
首先是recordBatch的控制信息
| 内容 | 释义 |
|---|---|
| 00 00 00 00 00 00 00 00 | baseOffset = 0 |
| 00 00 00 94 | legth = 144 |
| 00 00 00 00 | partitionLeaderEpoch = 0 |
| 02 | magic = 2 |
| c1 0d 4b b7 | crc |
| 00 00 | attributes |
| 00 00 00 04 | lastOffsetDelta = 4 |
| 00 00 01 7a 55 8b 99 9c | firstTimestamp |
| 00 00 01 7a 55 8b a7 5f | maxTimestamp |
| ff ff ff ff ff ff ff ff | producerId = -1 |
| ff ff | producerEpoch = -1 |
| 00 00 00 00 | baseSequence = 0 |
| 00 00 00 05 | recordCount = 5 |
然后是第一个record的信息
| 内容 | 释义 |
|---|---|
| 24 | length = varint(0x24) = 18 |
| 00 | attributes |
| 00 | timestampDelta |
| 00 | offsetDelta = 0 |
| 08 | keyLength = varint(0x8) = 4 |
| 74 65 63 68 | key = “tech” |
| 10 | valueLen = varint(0x10) = 8 |
| 66 6f 72 20 67 6f 6f 64 | value = “for good” |
| 00 | headerCounts = varint(0x00) = 0 |
再解析下第二个record的信息
| 内容 | 释义 |
|---|---|
| 26 | length = varint(0x26) = 19 |
| 00 | attributes |
| 8e 06 | timestampDelta |
| 02 | offsetDelta = varint(0x02) = 1 |
| 08 | keyLength = varint(0x8) = 4 |
| 74 65 63 68 | key = “tech” |
| 10 | valueLen = varint(0x10) = 8 |
| 66 6f 72 20 67 6f 6f 64 | value = “for good” |
| 00 | headerCounts = varint(0x00) = 0 |
……
参考资料:
https://kafka.apache.org/documentation/
https://developers.google.com/protocol-buffers/docs/encoding