原文链接:https://sookocheff.com/post/kafka/kafka-in-a-nutshell/
Kafka is a messaging system. That’s it. So why all the hype? In reality messaging is a hugely important piece of infrastructure for moving data between systems. To see why, let’s look at a data pipeline without a messaging system.
kakfa是一个消息系统。就这样。那为啥这么大肆宣传呢?事实上,在系统间传输数据时,消息是一个很重要的基础结构。想知道为什么,让我们看看没有消息系统的数据管道。
This system starts with Hadoop for storage and data processing. Hadoop isn’t very useful without data so the first stage in using Hadoop is getting data in.
这个系统起源于使用Hadoop进行存储和数据处理。Hadoop在没有数据时不是很有用,所以第一步是使用Hadoop获取数据。
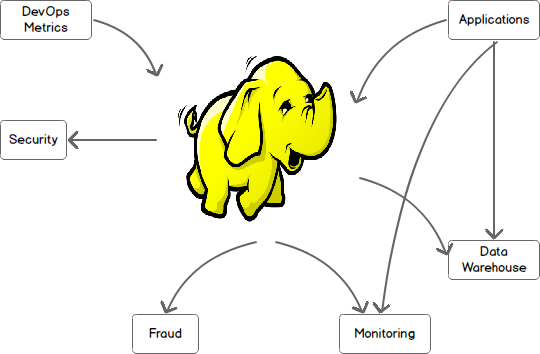
So far, not a big deal. Unfortunately, in the real world data exists on many systems in parallel, all of which need to interact with Hadoop and with each other. The situation quickly becomes more complex, ending with a system where multiple data systems are talking to one another over many channels. Each of these channels requires their own custom protocols and communication methods and moving data between these systems becomes a full-time job for a team of developers.
至此,还没啥。不幸的是,现实世界中的数据并行存在多个系统中,而且需要进行系统间或与Hadoop间的交互。情况马上就变复杂了,多个数据系统间要进行沟通需要通过很多的信道。这些信道要求它们自定义协议和沟通方式,使得这些系统间的数据传输可能会占用一组开发者的全部时间。
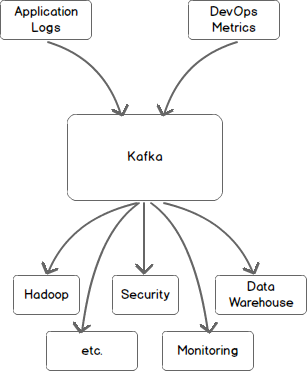
Let’s look at this picture again, using Kafka as a central messaging bus. All incoming data is first placed in Kafka and all outgoing data is read from Kafka. Kafka centralizes communication between producers of data and consumers of that data.
再看看这张图,使用Kafka作为中心信息总线。所有输入的数据都先放入Kafka,所有输出的数据都从Kafka读出。Kafka成为了数据生产者和数据消费者交互的中心。
什么是Kafka?(What is Kafka?)
Kafka is a distributed messaging system providing fast, highly scalable and redundant messaging through a pub-sub model. Kafka’s distributed design gives it several advantages. First, Kafka allows a large number of permanent or ad-hoc consumers. Second, Kafka is highly available and resilient to node failures and supports automatic recovery. In real world data systems, these characteristics make Kafka an ideal fit for communication and integration between components of large scale data systems.
Kafka是一个通过发布-订阅模型提供快速、高扩展和高吞吐量的分布式消息传输系统。Kafka的分布式设计提供了多种优势。第一,Kafka接受大量的永久或特定的消费者;第二,Kafka具有高可用性,能接受节点失败且支持自动恢复。在实际的数据系统中,这些特性使得Kafka完美符合大型数据系统组件之间通信和集成的要求。
Kafka 术语(Kafka Terminology)
The basic architecture of Kafka is organized around a few key terms: topics, producers, consumers, and brokers.
Kafka的基础架构由这么几个部件组成:主题(topics)、生产者(producers)、消费者(consumers)和brokers。
All Kafka messages are organized into topics. If you wish to send a message you send it to a specific topic and if you wish to read a message you read it from a specific topic. A consumer pulls messages off of a Kafka topic while producers push messages into a Kafka topic. Lastly, Kafka, as a distributed system, runs in a cluster. Each node in the cluster is called a Kafka broker.
所有的Kafka消息都会被归类为topics。如果你想发送消息,你可以将其发送到特定topic;如果想读取消息,则可以从特定topic读取。只有当producers推送消息到Kafka的topic,consumer才能从该Kafka topic中获取消息。最后,Kafka作为一个分布式系统,可以使用集群。集群中的每个节点称为broker。
Kafka主题剖析(Anatomy of a Kafka Topic)
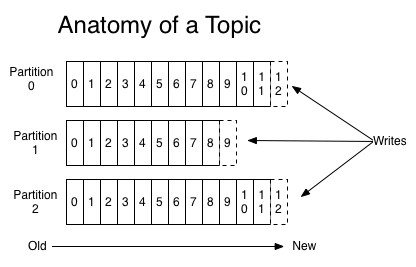
Kafka topics are divided into a number of partitions. Partitions allow you to parallelize a topic by splitting the data in a particular topic across multiple brokers — each partition can be placed on a separate machine to allow for multiple consumers to read from a topic in parallel. Consumers can also be parallelized so that multiple consumers can read from multiple partitions in a topic allowing for very high message processing throughput.
Kafka主题被分为了几个分区(partitions)。分区允许通过多个brokers拆分特定主题的数据实现topic并发,每个分区都能放在一台独立的机器上,并允许多个消费者并行读取一个主题。消费者也可以并行化,所以,多个消费者可以读取一个主题的多个分区以实现消息处理的高吞吐量。
Each message within a partition has an identifier called its offset. The offset the ordering of messages as an immutable sequence. Kafka maintains this message ordering for you. Consumers can read messages starting from a specific offset and are allowed to read from any offset point they choose, allowing consumers to join the cluster at any point in time they see fit. Given these constraints, each specific message in a Kafka cluster can be uniquely identified by a tuple consisting of the message’s topic, partition, and offset within the partition.
分区中的每个消息都有个标识称为偏移(offset)。消息的偏移顺序是一个不可变的序列。Kafka为你维持了这个消息顺序。消费者可以从一个特定的偏移开始读取消息,Kafka允许他们从选择的任意偏移节点读取,也允许消费者在他们认为合适的时间点加入集群。考虑这些限制,Kafka集群中的每条特定消息都可以被这么组元组唯一标识:[topic, partition, offset]
Another way to view a partition is as a log. A data source writes messages to the log and one or more consumers reads from the log at the point in time they choose. In the diagram below a data source is writing to the log and consumers A and B are reading from the log at different offsets.
查看分区的另一种方法是日志。一个数据源将消息写入日志,一个或多个消费者在他们选择的时间读取日志。下图中一个数据源正在向日志中写数据,消费者A和B正在不同的偏移中读取日志。
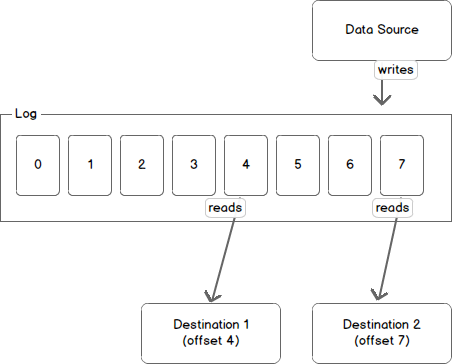
Kafka retains messages for a configurable period of time and it is up to the consumers to adjust their behaviour accordingly. For instance, if Kafka is configured to keep messages for a day and a consumer is down for a period of longer than a day, the consumer will lose messages. However, if the consumer is down for an hour it can begin to read messages again starting from its last known offset. From the point of view of Kafka, it keeps no state on what the consumers are reading from a topic.
Kafka保留消息的时间是可以配置的,并且消费者可以据此自行调整读取行为。例如,如果Kafka配置成保留消息一天,而一个消费者超过一天后消费,该消费者将会丢失消息。如果消费者一个小时后消费,他能从上次知道的偏移处再次开始读取信息。从Kafka的角度看,它不保存消费者读取某个主题的状态。
Partitions and Brokers
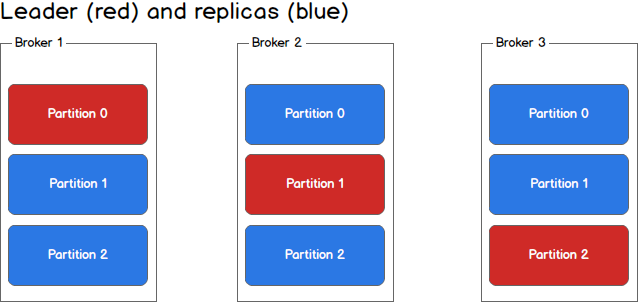
Each broker holds a number of partitions and each of these partitions can be either a leader or a replica for a topic. All writes and reads to a topic go through the leader and the leader coordinates updating replicas with new data. If a leader fails, a replica takes over as the new leader.
每个broker可以维持多个分区,而且每个分区可以是一个主题的leader或replica。所有对主题的读写都通过leader,然后leader协调向replica更新新数据。如果leader发生了故障,会选择一个replica成为新leader。
生产者(Producers)
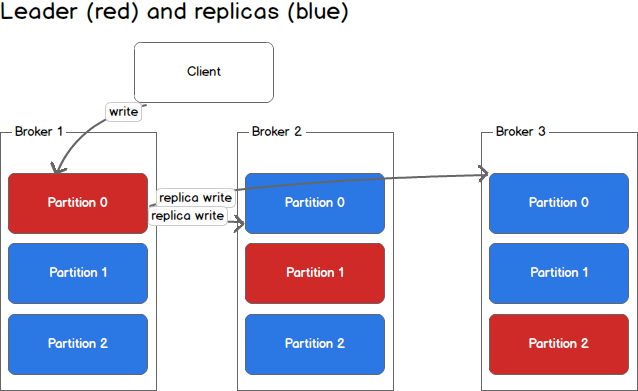
Producers write to a single leader, this provides a means of load balancing production so that each write can be serviced by a separate broker and machine. In the first image, the producer is writing to partition 0 of the topic and partition 0 replicates that write to the available replicas.
生产者只写向一个leader,这提供了一种负载均衡的生产方式,即每个写操作能由不同的broker和机器负责。在第一张图中生产者写向主题的分区0,然后分区0将其更新到其它可用replicas。
In the second image, the producer is writing to partition 1 of the topic and partition 1 replicates that write to the available replicas.
在第二张图中生产者写向主题的分区1,然后分区1将其备份到其它可用replicas。
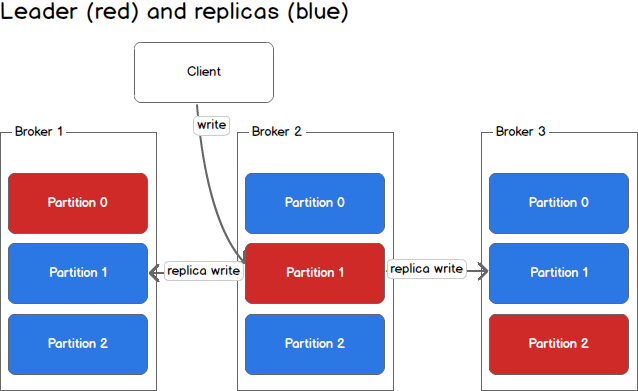
Since each machine is responsible for each write, throughput of the system as a whole is increased.
由于一台机器负责一次写操作,系统整体的吞吐量是提升的。
消费者和消费群组(Consumers and Consumer Groups)
Consumers read from any single partition, allowing you to scale throughput of message consumption in a similar fashion to message production. Consumers can also be organized into consumer groups for a given topic — each consumer within the group reads from a unique partition and the group as a whole consumes all messages from the entire topic. If you have more consumers than partitions then some consumers will be idle because they have no partitions to read from. If you have more partitions than consumers then consumers will receive messages from multiple partitions. If you have equal numbers of consumers and partitions, each consumer reads messages in order from exactly one partition.
消费者可以从任意一个分区读,其提升消息消费吞吐量的方式与生产消息类似。对某一主题而言,消费者也能够组成消费群组,组中的每一个消费者从单独的分区读,而消费组整体消费整个主题的消息。如果消费者的数量多于分区的数量,那么有些消费者会因为没有分区可读而空闲。如果分区数量多于消费者数量,那么消费者将接收多个分区的消息。如果消费者跟分区数量一样多,每个消费者按顺序地从一个分区中读取消息。
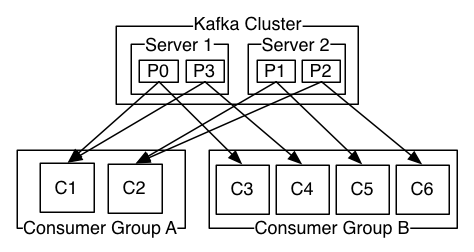
The following picture from the Kafka documentation describes the situation with multiple partitions of a single topic. Server 1 holds partitions 0 and 3 and server 2 holds partitions 1 and 2. We have two consumer groups, A and B. A is made up of two consumers and B is made up of four consumers. Consumer Group A has two consumers of four partitions — each consumer reads from two partitions. Consumer Group B, on the other hand, has the same number of consumers as partitions and each consumer reads from exactly one partition.
下面这张图来自Kafka文档,描述了一个主题多个分区的情况。其中,服务器1有分区0和3,服务器2有分区1和2。有两个消费者组A和B。A由两个消费者组成,B由4个消费者组成。A组两个消费对应4个分区——每个消费者从两个分区读。B组消费者与分区数目一致,每个消费者从一个分区读。
一致性和可用性(Consistency and Availability)
Before beginning the discussion on consistency and availability, keep in mind that these guarantees hold as long as you are producing to one partition and consuming from one partition. All guarantees are off if you are reading from the same partition using two consumers or writing to the same partition using two producers.
在讨论一致性和可用性之前,需要谨记下面的保证基于一个前提:只向一个分区写,只从一个分区读。如果有两个消费者从同一分区读或两个生产者向同一分区写,那么这些保证将失效。
Kafka makes the following guarantees about data consistency and availability: (1) Messages sent to a topic partition will be appended to the commit log in the order they are sent, (2) a single consumer instance will see messages in the order they appear in the log, (3) a message is ‘committed’ when all in sync replicas have applied it to their log, and (4) any committed message will not be lost, as long as at least one in sync replica is alive.
Kafka对数据一致性和可用性做出以下保证:
- 消息写入一个主题分区将按照写入顺序依次追加到确认日志
- 单个消费者实例将按照日志中的顺序读到消息
- 当所有同步replica(in sync replicas)都将消息写入日志,该消息才算被“确认”
- 只要一个同步replica还存活着,确认的消息就不会被丢失
The first and second guarantee ensure that message ordering is preserved for each partition. Note that message ordering for the entire topic is not guaranteed. The third and fourth guarantee ensure that committed messages can be retrieved. In Kafka, the partition that is elected the leader is responsible for syncing any messages received to replicas. Once a replica has acknowledged the message, that replica is considered to be in sync. To understand this further, lets take a closer look at what happens during a write.
前两条保证确保了消息在每个分区中是有序的。提醒一下,这并不确保整个主题中的消息是有序的。后两条保证确保了确认的消息是可以查找到的。在Kafka中,被选为leader的分区负责将收到的消息同步给replica。当一个replica收到了消息,就认为该replica是同步的。为了更好地理解这个,我们进一步看看在写的过程中发生了什么。
处理写(Handling Writes)
When communicating with a Kafka cluster, all messages are sent to the partition’s leader. The leader is responsible for writing the message to its own in sync replica and, once that message has been committed, is responsible for propagating the message to additional replicas on different brokers. Each replica acknowledges that they have received the message and can now be called in sync.
当与Kafka集群通信时,所有的消息都发送给了leader分区。leader负责向同步replica写消息,一旦该消息被确认,再负责向不同broker上的其余replica传播。每个确认收到了该消息的replica,都可称为是同步的。
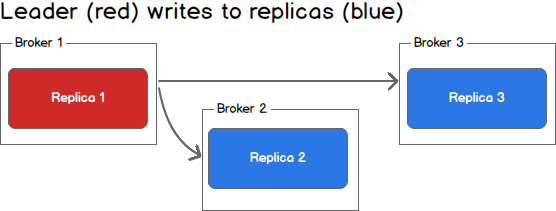
When every broker in the cluster is available, consumers and producers can happily read and write from the leading partition of a topic without issue. Unfortunately, either leaders or replicas may fail and we need to handle each of these situations.
当集群中的所有broker都是可用的,消费者和生产者能轻松无误地从主题的leader分区中读写。不幸的是,leader和replica都是可能发生故障的,我们需要去处理这些状况。
处理故障(Handling Failure)
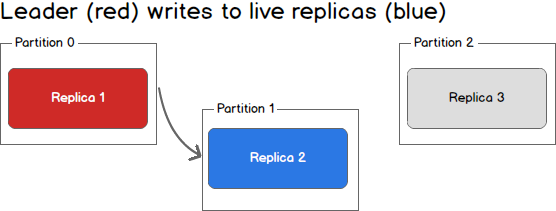
What happens when a replica fails? Writes will no longer reach the failed replica and it will no longer receive messages, falling further and further out of sync with the leader. In the image below, Replica 3 is no longer receiving messages from the leader.
当一个replica故障时会发生什么?写操作送不到故障的replica,并且其不再能接受消息,会远远落后于leader。如下图,replica 3不再能从leader接收消息。
What happens when a second replica fails? The second replica will also no longer receive messages and it too becomes out of sync with the leader.
当第二个replica故障时又会发生什么?第二个replica同样不能接收消息,而且也会落后于leader。
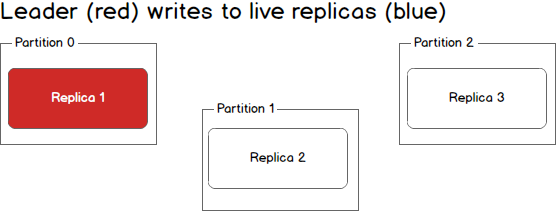
At this point in time, only the leader is in sync. In Kafka terminology we still have one in sync replica even though that replica happens to be the leader for this partition.
此时,只有leader处于同步状态。在Kafka的概念中,我们还有一个同步的replica,虽然该replica是分区的leader。
What happens if the leader dies? We are left with three dead replicas.
leader挂了又会发生什么呢?我们只留下了3个挂了的replica。
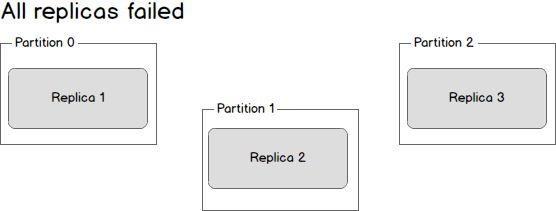
Replica one is actually still in sync — it cannot receive any new data but it is in sync with everything that was possible to receive. Replica two is missing some data, and replica three (the first to go down) is missing even more data. Given this state, there are two possible solutions. The first, and simplest, scenario is to wait until the leader is back up before continuing. Once the leader is back up it will begin receiving and writing messages and as the replicas are brought back online they will be made in sync with the leader. The second scenario is to elect the second broker to come back up as the new leader. This broker will be out of sync with the existing leader and all data written between the time where this broker went down and when it was elected the new leader will be lost. As additional brokers come back up, they will see that they have committed messages that do not exist on the new leader and drop those messages. By electing a new leader as soon as possible messages may be dropped but we will minimized downtime as any new machine can be leader.
replica 1实际上还是处于同步状态的,虽然它不能接收任何新的消息,但是它在能接收到消息的时候是同步的。replica 2会丢失一些数据,replica 3(最先挂的那位)会丢失更多的数据。在这种状况下,有两种解决方案。
- 第一种最简单的方案是在继续之前等待leader恢复。一旦leader恢复,它将再次开始读写消息,等replica恢复后,它们将再次与leader进行同步。
- 第二种是选择另一个broker恢复并选其为leader。这个broker是落后于现存的leader的,而且所有在该broker挂掉到它被选为leader这段时间写入的消息都会丢失。别的broker恢复的时候,会发现它们有些已确认的消息在新的leader中是没有的,它们会丢掉这些消息。虽然选择新的leader会丢失一些消息,但是我们可以尽可能快地选择任意机器成为leader,以此来降低损耗。
Taking a step back, we can view a scenario where the leader goes down while in sync replicas still exist.
返回之前,我们来看看当leader挂了,但同步replica还正常的情况。
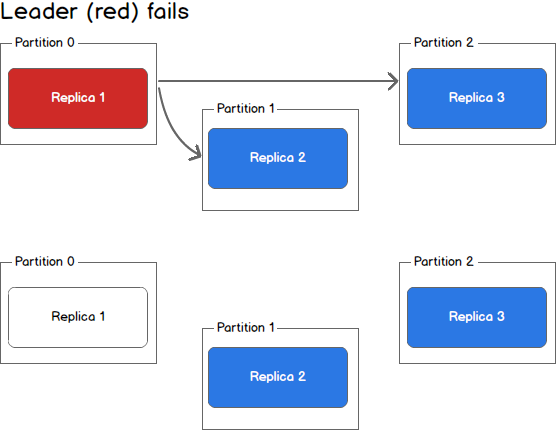
In this case, the Kafka controller will detect the loss of the leader and elect a new leader from the pool of in sync replicas. This may take a few seconds and result in LeaderNotAvailable errors from the client. However, no data loss will occur as long as producers and consumers handle this possibility and retry appropriately.
在这种情况下,Kafka控制器将检测到leader挂机了,会从同步replica中选出一位新的leader。这会消耗几秒钟,会导致客户端显示LeaderNotAvailable错误。但是,只要生产者和消费者发现这种情况后正常地重试,就不会有数据损失。
Kafka客户端的一致性(Consistency as a Kafka Client)
Kafka clients come in two flavours: producer and consumer. Each of these can be configured to different levels of consistency.
Kafka客户端有两种:生产者和消费者。二者都有不同级别的一致性可以配置。
For a producer we have three choices. On each message we can (1) wait for all in sync replicas to acknowledge the message, (2) wait for only the leader to acknowledge the message, or (3) do not wait for acknowledgement. Each of these methods have their merits and drawbacks and it is up to the system implementer to decide on the appropriate strategy for their system based on factors like consistency and throughput.
对于一条消息,生产者有三种选择:
- 等所有同步replica都获得该消息
- 只等leader获取该消息
- 不等
这几种方法都有自己的优缺点,使用者可以根据系统的一致性和吞吐量来决定合适的策略。
On the consumer side, we can only ever read committed messages (i.e., those that have been written to all in sync replicas). Given that, we have three methods of providing consistency as a consumer: (1) receive each message at most once, (2) receive each message at least once, or (3) receive each message exactly once. Each of these scenarios deserves a discussion of its own.
对于消费者来说,只能读到已确认的消息(例如:那些已经被写入所有同步replica的消息)。基于此情况,我们同样为消费者提供了3个级别的一致性选择:
- 每条消息至多接收一次
- 每条消息至少接收一次
- 每条消息只接受一次
需要自行确定使用哪种。
For at most once message delivery, the consumer reads data from a partition, commits the offset that it has read, and then processes the message. If the consumer crashes between committing the offset and processing the message it will restart from the next offset without ever having processed the message. This would lead to potentially undesirable message loss.
至多接收一次消息时,消费者从一个分区中读出数据,确认了已读的消息(offset),然后处理消息。如果消费者在确认消息和处理消息之间发生故障了,它将从下一消息(offset)重启,该消息将不会被处理。这可能导致重要消息丢失。
A better alternative is at least once message delivery. For at least once delivery, the consumer reads data from a partition, processes the message, and then commits the offset of the message it has processed. In this case, the consumer could crash between processing the message and committing the offset and when the consumer restarts it will process the message again. This leads to duplicate messages in downstream systems but no data loss.
不想数据丢失的选择是至少接收一次。消费者从一个分区读取数据,先处理数据,再处理完之后再确认该消息(offset)。在这种情况下,消费者在处理和确认消息之间发生故障,再重启仍然会处理该消息。这会导致下游出现重复的消息,但不会丢失消息。
Exactly once delivery is guaranteed by having the consumer process a message and commit the output of the message along with the offset to a transactional system. If the consumer crashes it can re-read the last transaction committed and resume processing from there. This leads to no data loss and no data duplication. In practice however, exactly once delivery implies significantly decreasing the throughput of the system as each message and offset is committed as a transaction.
每条消息只接收一次是通过消费者处理消息,然后将消息处理的结果和offset提交到交易系统来保证的。如果消费者故障,能从上一次提交的交易恢复,并从这开始处理。这将不会发生数据的丢失和重复。然而,每次消息和偏移都当成交易进行确认会显著降低系统的吞吐量。
In practice most Kafka consumer applications choose at least once delivery because it offers the best trade-off between throughput and correctness. It would be up to downstream systems to handle duplicate messages in their own way.
实际上,大部分Kafka消费者应用选择至少接受一次消息,因为提供了吞吐量与准确性之间的最佳平衡。它将重复消息的处理扔给了下游系统。
总结(Conclusion)
Kafka is quickly becoming the backbone of many organization’s data pipelines — and with good reason. By using Kafka as a message bus we achieve a high level of parallelism and decoupling between data producers and data consumers, making our architecture more flexible and adaptable to change. This article provides a birds eye view of Kafka architecture. From here, consult the Kafka documentation. Enjoy learning Kafka and putting this tool to more use!
Kafka有充分的理由能也正在快速地成为很多机构数据管道的基石。通过使用Kafka作为消息总线,我们能实现消息生产者和消费者之间高水平地并行和解耦,使我们的架构更灵活多变。本文只是提供了Kafka架构的鸟瞰图。更多的可参考Kafka文档。享受学习Kafka然后更多地使用它。